Stratégie de CI/CD sur Kubernetes - Cellenza Blog
A propos de l'auteur Mustapha Ferhaoui
20-25 minutes
Article corédigé par Mustapha Ferhaoui et Jérôme Thin
Nous allons à présent aborder les notions d'usine logiciel au sein de l'écosystème Kubernetes. Mais avant de rentrer dans le vif du sujet, il est indispensable d'avoir quelques notions d'industrialisation sur les mises en pratique d'une bonne CI/CD pour booster votre productivité. Nous allons donc commencer par quelques définitions.

La CI désigne l'intégration continue, à savoir un processus d'automatisation pour les développeurs. Cette intégration continue consiste, pour les développeurs, à apporter régulièrement des modifications au code de leur application, à les tester, puis à les fusionner dans un référentiel partagé. Cette solution permet de fluidifier le processus de développement mais aussi d'éviter les régressions.
La CD peut désigner la "distribution continue" ou le "déploiement continu", deux concepts très proches, parfois utilisés de façon interchangeable.

Ce qu'il faut retenir, c'est que :
- La CI permet d'automatiser les développements à des fins qualitatives, afin de produire des releases ;
- La CD vous permettra de déployer automatiquement vos releases sur vos environnements de test puis de production.
C'est un bon moyen de booster votre productivité.
Dans ce qui va suivre, nous allons évoquer certains points incontournables de la CI/CD pour Kubernetes :
- Comment créer et gérer ses clusters Kubernetes pour héberger ses applications ?
- Comment déployer ses applications sur Kubernetes ?
Infrastructure as Code (IaC) : création et gestion du cluster Kubernetes
L'Infrastructure as Code (IaC) est une méthodologie permettant de gérer l'automatisation de votre infrastructure. Tout se trouve dans votre repository Git.
Certaines grandes entreprises recréent de toutes pièces leur infrastructure chaque semaine. L'automatisation devient gage de sureté. Face à un disaster recovery, vous pourrez plus aisément vous fier à votre IaC.
Afin de créer et gérer vos clusters Kubernetes, nous vous recommandons de procéder de cette manière.
L'approche procédurale
Lorsque nous abordons notre infrastructure avec une approche procédurale, cela revient à se dire "Comment mon infrastructure devrait être changée ?"
C'est une méthode itérative dans laquelle vous allez mettre en place vos différents scripts d'automatisation afin de consolider votre infrastructure.
L'inconvénient majeur de cette approche est que vous devez continuellement vérifier l'état réel de votre infrastructure. Au fil du temps, cette dernière s'étoffera et vous risquez d'en perdre le contrôle.
L'approche déclarative
Les solutions pour l'approche déclarative
L'approche déclarative consiste à définir l'infrastructure souhaitée (propriétés, ressources nécessaires, dépendances...) et l'outil IaC se chargera de la configuration.
Les principaux outils fournis par défaut par les Cloud providers sont :
- ARM / Bicep pour Azure
- CloudFormation pour AWS
- Cloud Deployment Manager pour GCP
- Etc.
Une autre alternative permet de décrire votre infrastructure pour les Cloud providers connus du marché : il s'agit de Terraform. A l'aide du même langage (HCL, pour Hashicorp Configuration Language), on applique le même workflow, quelle que soit la cible :
- Write : décrire l'infrastructure souhaitée ;
- Plan : vérifier les changements avant son application ;
- Apply : provisionnement et mise à jour de l'infrastructure.
On peut utiliser Terraform pour les cas suivants :
- Dans le cadre du multicloud: clusters Kubernetes sur deux Cloud providers différents par exemple ;
- Si vous avez un doute sur la cible et qu'un changement est envisagé dans un futur proche : passage d'un Cloud provider vers un autre par exemple.
Voici les principaux providers disponibles pour Terraform :

Quel que soit votre choix, les fichiers de configuration devront être stockés dans un système de contrôle de source tel que Git.
Le repository, reflet de notre infrastructure
Le fait de décrire l'infrastructure de manière déclarative dans votre repository permet d'avoir une seule source pour la création et la gestion des clusters Kubernetes. En effet, on évite ainsi d'interagir directement avec l'infrastructure pour toute modification de configurations tout en conservant un historique des modifications. Ce dernier pourrait même devenir source de documentation.
Partir d'un modèle pour créer d'autres environnements
A partir d'un modèle d'une infrastructure existante, il sera possible de créer d'autres environnements :
- Pour avoir d'autres environnements de test / recette ;
- Sur une autre zone géographique;
- Pour préparer une montée de version de Kubernetes avec les applications existantes et mesurer les impacts.
L'approche GitOps
Inventé récemment par Alexis Richardson de Weaveworks, GitOps est un modèle qui a beaucoup gagné en popularité. L'Infrastructure as Code nous accompagne depuis quelques années maintenant, depuis l'invention des Clouds publics où chaque ressource peut être définie comme du code. GitOps est une extension logique de cette idée aux applications exécutées dans Kubernetes. Le mécanisme de déploiement de Kubernetes nous permet de décrire complètement nos applications sous forme de manifestes que nous pouvons versionner dans Git.
La méthodologie GitOps va un peu plus loin sur l'approche déclarative. Les repositories Git deviennent la seule source de vérité. Toute modification manuelle de l'infra via l'interface utilisateur ou ligne de commande est proscrite.
Le repository Git de l'infrastructure doit être dissocié des repository applicatifs. Ils ont en effet chacun leur propre cycle de vie.
La CI va se dérouler sur le repository de l'application. La CI lancera :
- Le build applicatif ;
- Les tests unitaires ;
- Le build de l'image de l'application ;
- Et enfin, le push dans un registry.
Il existe 2 modes GitOps :
- Le mode Push
- Le mode Pull
Le mode Pull est l'approche la plus intuitive dans l'écosystème Kubernetes. Nous allons donc nous y intéresser de plus près :
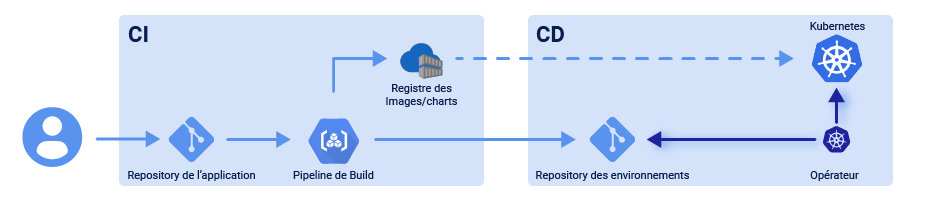
Les pipelines CI/CD traditionnels sont déclenchés par un événement externe, par exemple lorsqu'un nouveau code est poussé vers le repository de votre application. Avec l'approche de déploiement basée sur le Pull, une nouvelle notion est introduite : l'opérateur. Ce dernier reprend la responsabilité du pipeline en scrutant le repository de votre environnement. Il compare en permanence l'état souhaité avec l'état réel de l'infrastructure. Pour chaque différence constatée, l'opérateur met à jour l'infrastructure pour qu'elle corresponde au repository de votre environnement. L'opérateur peut aussi surveiller vos registries d'images afin de trouver de nouvelles versions d'images à déployer.
Argo CD, Flux et Jenkins X sont des outils de CD nouvelle génération adoptant la stratégie GitOps Pull.

Sur le plan architectural, GitOps nous permettra de séparer le flux d'intégration continue (CI) d'une application du processus de déploiement, car le processus de déploiement démarrera en fonction des modifications apportées à un dépôt GitOps, et non dans le cadre du processus CI.
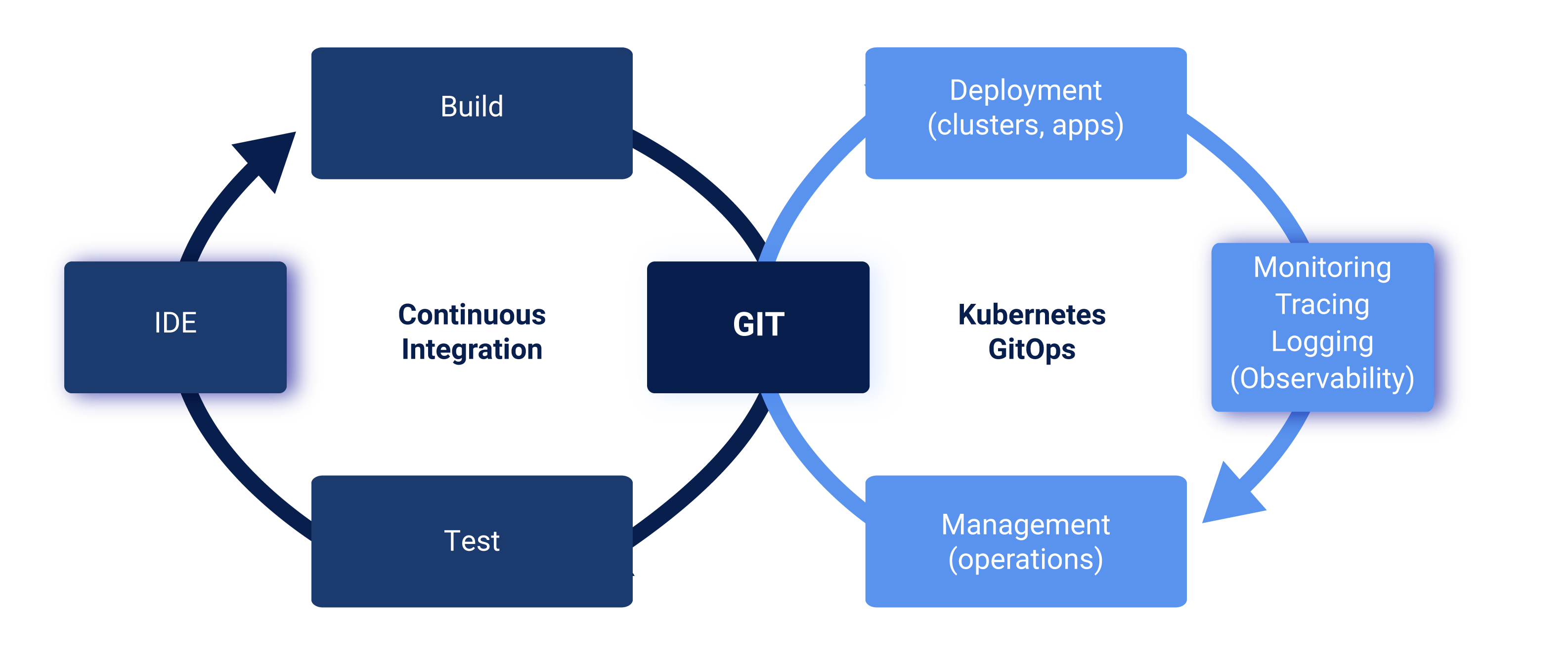
Nous allons maintenant aborder le sujet de la CI pour rentrer dans le vif du sujet concernant nos applications à conteneuriser.
Côté applicatif
La CI
Une CI Standard
Les étapes incontournables d'une CI sont :
- Le build ;
- Les tests unitaires ;
- Une publication de votre build dans un artefact.
Dans le cadre d'une intégration continue pour vos applications qui tourneront par la suite dans le cluster AKS, nul besoin de changer vos habitudes en matière de CI.
Le seul changement à apporter est de publier en fin de CI vos images Docker dans vos registries privés.
Les images de conteneur
Préparer son image ne se résume pas seulement à conteneuriser son application.
Il faut prendre en considération plusieurs éléments :
- Comment versionner mon application ?
- L'image source est-elle sécurisée ?
- Mon application génère-t-elle des logs ?
- Ces logs peuvent-ils me permettre d'avoir des KPIs métiers et de performance ?
- Mon application dispose-t-elle d'un healthcheck permettant de connaître son statut ?
Ségrégation des environnements de production et de développement
Au fil du temps, suite aux nombreuses features développées par vos équipes, vous vous retrouverez avec une multitude d'image taguées sur vos registries. Des tags très souvent inutiles et qui vous donnent l'impression de nager dans un nuage de tags.
Il devient donc utile de séparer vos travaux de développement avec ce que vous souhaitez réellement déployer en production.
Avoir un registry de développement séparé de la production permet de gagner en clarté.
Vous pouvez très bien pousser vos tags de développement depuis vos branches de feature et develop, et utiliser la branche master pour pousser vos tags de production.
Porter le versionning sur vos branches
En fonction de la taille de vos équipes, vous devez faire un choix sur l'adoption d'un flow Git : Git Flow, Github Flow, master only.
Et afin d'automatiser le versionning de votre application, vous pouvez tout simplement laisser cette responsabilité à vos branches.
Certains outils tels que Git Version permettent de mettre en place assez rapidement le versionning au sein de vos branches.

Il suffit alors d'utiliser la version de votre branche pour taguer vos images.
Pour le déploiement de vos applications, nous vous recommandons ne pas utiliser le tag latest. Il est préférable de toujours indiquer un tag de version, afin de garder une trace des déploiements pour pouvoir investiguer en cas de problème.
Les images utilisées sont-elles sécurisées ?
Nous avons tendance à rechercher l'image la plus petite, la moins consommatrice, au détriment de la sécurité.
Pour se prémunir de ces vulnérabilités, mieux vaut intégrer dans votre registry un outil de scan.
Très complet, le registry Harbor permet d'ajouter via un plugin des outils de scan comme Clair (open source).
Ne pas oublier le monitoring
Le monitoring est la clé du succès !
Lorsque vous développez vos applications, ne soyez pas avare en log. Mettez en place des logs afin de collecter des informations de performance ainsi que des KPIs métiers pertinents.
Ces customs metrics pourront alors remonter dans vos dashboards métiers et techniques.

La CD
Aujourd'hui, l'un des plus grands défis du développement d'applications Cloud natives est d'accélérer le nombre de vos déploiements. Avec une approche de microservices, les développeurs travaillent déjà avec et conçoivent des applications entièrement modulaires qui permettent à plusieurs équipes d'écrire et de déployer des modifications simultanément sur une application.
Des déploiements plus courts et plus fréquents offrent plusieurs avantages :
- Une réduction du time to market ;
- Les clients peuvent profiter des fonctionnalités plus rapidement ;
- Des feedbacks clients plus rapides.
Comment déployer sur Kubernetes ?
Kubectl est l'interface en ligne de commande (CLI) de Kubernetes. Il permet de déployer toutes sortes d'objets Kubernetes dans vos clusters.
Le format adopté par Kubernetes est le YAML (Yet Another Markup Language).
A travers ces commandes kubectl, vous pourrez transmettre ces manifestes afin de déployer au mieux vos applications.
Ce qu'il ne faut pas oublier pour vos containers
Gardez bien à l'esprit que vos applications sont déployées dans un environnement Kubernetes.
Vous devez prendre en compte un certain nombre de point clés.
Limitation CPU / Mémoire
Certaines mesures devront être prises en considération avant d'embarquer votre application dans un cluster.
Effectuez des load tests afin de connaître les limitations de votre application. Ils vous permettront de définir :
- Sa consommation mémoire ;
- Son utilisation CPU (Central Processing Unit) ;
- Le nombre de requêtes par seconde qu'elle peut gérer.
Ces informations vont être capitales par la suite pour définir la haute disponibilité de vos applications.
Définir vos limitations vous permettra d'utiliser efficacement vos Horizontal Pod Autoscaler (HPA).
Si votre cluster dispose d'un autoscaling, cela sera d'autant plus bénéfique pour l'hyper-scalabilité de vos applications. Sans limitation définie, l'autoscaling devient inutile.
 Source : Documentation Microsoft
Source : Documentation Microsoft
HealthCheck
Tout Load Balancer a besoin de scruter la santé des applications avant de router dessus. Kubernetes ne déroge pas à la règle.
Prenez le temps de mettre en place un HealthCheck dans votre application afin que votre cluster puisse interroger un pod sain.
Nous avons pu voir à de nombreuses reprises des applications sans monitoring ni HealthCheck. Le problème récurrent est que votre service (ingress) redirige vers des pods en erreur (applicative) et le diagnostic devient compliqué.
Une fois le Healthcheck mis en place sur vos applications, il faut aussi prendre le temps de configurer les probes de vos containers.
Il existe 3 types de sondes :
- Startup probe : vérifie le démarrage initial de vos applications. Elle n'est utilisée qu'une seule fois.
- Readiness probe : vérifie si votre application peut répondre au trafic. Elle est utilisée tout le long de la vie de votre conteneur. En cas d'échec, Kubernetes arrêtera d'acheminer le trafic vers votre application (et essayera plus tard).
- Liveness probe : vérifie si votre application est en bon état de fonctionnement. Elle est utilisée tout le long de la vie de votre conteneur. En cas d'échec, Kubernetes supposera que votre application est bloquée et la redémarrera.
Stratégie de déploiements
Il existe plusieurs types de stratégies de déploiement dont vous pouvez tirer parti en fonction de votre objectif.
Stratégie Rolling Update
Le Rolling Update -- ou déploiement progressif -- est le déploiement standard par défaut sur Kubernetes. Il fonctionne lentement, un par un, en remplaçant les pods de la version précédente de votre application par des pods de la nouvelle version, sans aucun temps d'arrêt du cluster, permettant aussi un rollback automatique en cas d'échec.

Stratégie Blue-Green
Dans une stratégie de déploiement Blue-Green, deux versions de votre application coexistent :
- L'ancienne version de l'application (Blue), qui est celle vue par les utilisateurs ;
- La nouvelle version (Green), qui est en cours de développement.
Une fois la nouvelle version testée et validée pour la publication, le service passe à la version Green avec l'ancienne version Blue qui devient le slot de la future release.

Stratégie Canary Release
Le Canary est utile lorsque vous souhaitez tester de nouvelles fonctionnalités, généralement sur le backend de votre application, avec précaution.
Deux applications coexistent alors dans votre infrastructure :
- L'application actuelle ayant la quasi-totalité du trafic ;
- L'application disposant de la nouvelle feature que nous souhaitons éprouver avec un trafic régulé.
Vos clients et développeurs pourrons alors tester ces nouvelles fonctionnalités.
Lorsqu'aucune erreur n'est signalée sur les plans technique et fonctionnel, la nouvelle version peut progressivement se déployer sur le reste de l'infrastructure en prenant la place de l'ancienne.
Sa mise en place est plus facile avec un Service Mesh tel qu'Istio.
 Source : documentation Istio
Source : documentation Istio
Stratégie d'A/B Testing
L'A/B Testing rejoint beaucoup le concept de Canary et est plus destiné aux fonctionnalités front-end.
Plutôt que de lancer une nouvelle fonctionnalité pour tous les utilisateurs, vous pouvez la proposer à un petit nombre d'entre eux. Les utilisateurs ne savent généralement pas qu'ils sont utilisés comme testeurs pour la nouvelle fonctionnalité.
A l'aide de métriques/KPIs, vous pourrez alors observer l'efficacité de votre nouvelle interface utilisateur : permet-elle d'avoir une belle conversion business ? Est-elle trop déroutante pour vos utilisateurs ?
Une fois de plus, sa mise en pratique est plus aisée via un Service Mesh dans vos clusters.

Vue d'ensemble des stratégies de déploiement

Industrialiser ses packages avec Helm
Dans Kubernetes, la configuration de vos services/applications se fait généralement via des fichiers YAML. Quand on a une seule application en ligne, cela reste assez simple mais dès qu'on a plusieurs environnements, applications et services, on se retrouve très vite submergé de fichiers plus ou moins semblables.
C'est là qu' intervient Helm !
Helm est le package manager soutenu et recommandé par Kubernetes. Il est aussi l'un des seuls sur le marché, son unique concurrent, KPM de CoreOS, n'étant plus maintenu depuis juillet 2017.
Pourquoi Helm ?
Toutes les solutions de création de modèles pour Kubernetes souffrent du même problème : Kubernetes ne connaît qu'un ensemble de manifestes et rien de plus. La notion d'application est perdue et ne peut être recréée qu'en ayant les fichiers sources d'origine à portée de main.
Helm, quant à lui, connaît l'ensemble de l'application et stocke les informations spécifiques à l'application dans le cluster lui-même. Il peut alors suivre les ressources de l'application suite au déploiement. La différence est subtile mais importante.
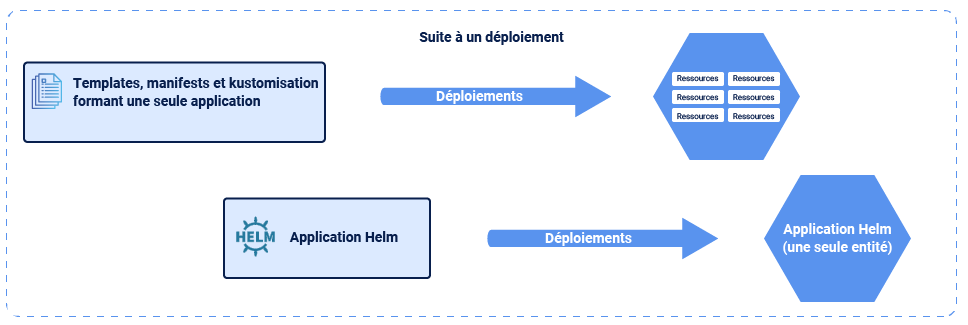
Il est inutile de comparer Helm aux outils de création de modèles tels que Kustomize / k8compt / kdeploy : Helm est bien plus qu'une solution de création de modèles.
Ce package manager présente d'autres avantages :
- Moteur de templating permettant de factoriser les manifestes YAML de toutes vos applications ;
- Organisation et unification de vos templates avec une arborescence cohérente ;
- Mise à disposition de vos charts sur des dépôts publics ou privés ;
- Update et Rollbacks des révisions de vos applications sans rupture de service ;
- Système de dépendance avec d'autres charts (encore plus de factorisation) ;
- Test via le CLI pour vérifier les connectivités.
 Illustration de rollbacks automatiques basés sur vos métriques afin d'éviter certaines catastrophes.
Illustration de rollbacks automatiques basés sur vos métriques afin d'éviter certaines catastrophes.
Vous allez pouvoir unifier et simplifier vos centaines de manifestes YAML Kubernetes en quelques charts. Terminé les duplications de configuration !
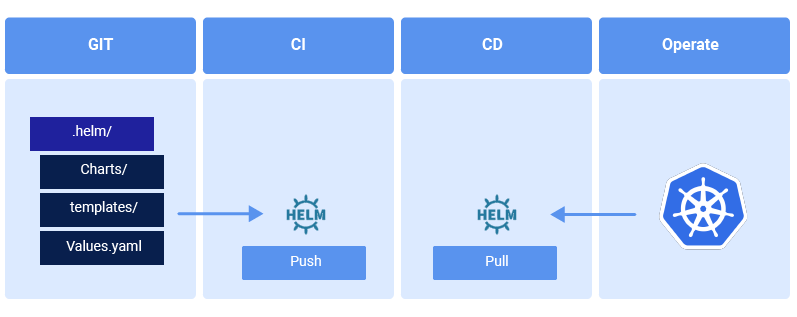
Comment Intégrer Helm dans vos pipelines CI/CD ?
L'intégration de vos packages Helm dans votre CI demande peu de modifications de votre CI.
Voici le schéma d'une approche classique :

Et celui d'une approche GitOps en mode Pull :

Dans les 2 cas :
- Vous devez stocker vos charts dans vos repository Helm lors de la CI ;
- Vous pourrez alors en disposer lors de votre CD.
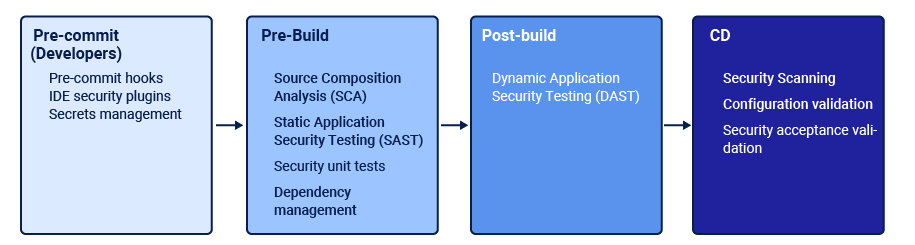
Intégrer la sécurité dans vos pipelines CI/CD
Une fois vos pipelines CI/CD mises en place et fonctionnelles, vous avez la possibilité d'ajouter des tâches supplémentaires et de faire certaines vérifications avant d'exécuter chaque tâche de votre pipeline. Cela pourra créer des rapports, bloquer la pipeline, vous avertir en cas de problème...
La plupart du temps, vous allez utiliser des outils open-source ou des produits éditeurs.
Vous pouvez par exemple :
- Vérifier la présence de données sensibles (secrets, respect des bonnes pratiques de développement) ;
- Analyser le code source (applicatif, IaC) ;
- Rechercher les vulnérabilités sur les dépendances projets ;
- Lancer des tests de sécurité sur les images de conteneurs ;
- Vérifier l'intégrité de votre image de conteneur.
L'essentiel à retenir
Nous avons pu voir ensemble les éléments clés qu'il ne faut surtout pas mettre de côté lors de la création de votre infrastructure ainsi que l'importance de la mise en place d'une bonne CI/CD.
Dans le cadre d'une modernisation de vos applications Cloud native, il est judicieux de mettre en place une automatisation performante afin de réduire le time to market.
Sur la partie infrastructure, partir d'un template est bénéfique afin de suivre l'évolution des clusters Kubernetes mais aussi de le réutiliser pour différents cas d'usage, comme déployer d'autres environnements et la mise à jour de Kubernetes dans le cadre du Blue/Green. Nous recommandons fortement l'IaC.
L'écosystème de Kubernetes est en perpétuel mouvement. Il n'est donc pas aisé de se retrouver avec cette multitude d'outils proposés par la toile. Les montées de version de vos clusters sont elles aussi conséquentes !
Il est donc indispensable d'être à l'écoute des technos et de vous adapter en continu. Et aussi d'avoir une rigueur dans la mise en place de vos configurations et sans cesse optimiser vos processus : configuration des ressources, policy, sécurité, monitoring...
Pour aller plus loin sur Kubernetes
Pour mettre en pratique tout ce que vous avez appris au cours du Mois du Conteneur, Cellenza vous propose de voir le replay du webinaire de clôture. Pendant une heure, Benoît Sautière (Senior Technical Officer chez Cellenza), Stanislas Quastana (Cloud Solution Architect chez Microsoft) et Louis-Guillaume Morand (Cloud Solution Architect chez Microsoft) vous présentent les différentes étapes à suivre pour adopter Kubernetes dans votre entreprise !
Retrouvez également tous les articles du Mois du Conteneur :
- Un mois pour tout savoir sur Kubernetes
- Kubernetes : quel intérêt pour répondre aux enjeux Business ?
- Kubernetes au service de votre stratégie applicative
- Kubernetes : un écosystème à construire
- Mettre en place sa stratégie de migration vers Kubernetes
- Comment intégrer Kubernetes dans sa stratégie de monitoring ?
- Sécuriser son service Kubernetes
Tous ces articles sont compilés dans un livre blanc téléchargeable gratuitement.

Article rédigé par Mustapha Ferhaoui et Jérôme Thin